Буквально на днях на arXiv-е была выложена очень занятная статья швейцарских исследователей, в которой представлены подробности проекта LLHD. Это проект создания многоуровневого промежуточного представления для языков описания аппаратуры, наследующий идеологию и принципы проекта LLVM.
Говоря простыми словами — это новый язык описания аппаратуры, лишенный недостатков его предшественников и уже сейчас демонстрирущий приличную производительность, гибкость и совместимость с существующей инфраструктурой. Приятным моментом является то, что код основных инструментов написан на языке Rust.
 Предлагаемая иерархия инструментов (здесь и далее изображения из оригинальной статьи)
Предлагаемая иерархия инструментов (здесь и далее изображения из оригинальной статьи)
У проекта есть все шансы стать тем же, чем GCC и LLVM в свое время стали для мира открытого программного обеспечения. Сложно даже представить, насколько это может изменить ситуацию вокруг разработки железа.
Под катом описание текущего положения дел, краткий обзор языка и отличия нового подхода.
Введение
Очень долгое время разработка аппаратуры оставалась уделом махровой проприетарщины, где все разработки и взаимодействие тотально обложены NDA, да и патентами тоже особо никто делиться не собирается. Все начало меняться с появлением серии проектов, ставящих своей целью обратную разработку архитектуры и формата прошивок ПЛИС и создания полностью открытого тулчейна, позволяющего выполнять все этапы разработки прошивки для поддерживаемых ПЛИС: от парсинга HDL до симуляции, формальной верификации, размещения компонентов и маршрутизации связей и синтеза образа (bitstream), который загружается в ПЛИС. Благодаря этому сейчас возможно создание прошивок целиком с помощью открытого тулчейна для ПЛИС Lattice iCE40 (проект iCE Storm), ECP5 (проект Trellis) и, частично, для Xilinx 7 серии (проект X-Ray).
Однако, по-прежнему масла в огонь подливает весьма своеобразная иерархия инструментов. По факту, существует два основных языка описания аппаратуры: Verilog и VHDL. Оба родом из восьмидесятых и, на современный взгляд, чрезмерно многословны и негибки. Разработчикам приходится с этим мириться, ибо альтернатив в общем-то и нет: мало просто разработать новый язык описания аппаратуры, нужно еще интегрировать его в весьма консервативное окружение. Поэтому даже современные языки, такие как Chisel, вынуждены транслироваться в Verilog и VHDL. То есть, результатом работы компилятора будет не конечный код, а все тот же Verilog, который будет заново транслироваться и использоваться другими инструментами на каждом этапе разработки и тестирования.
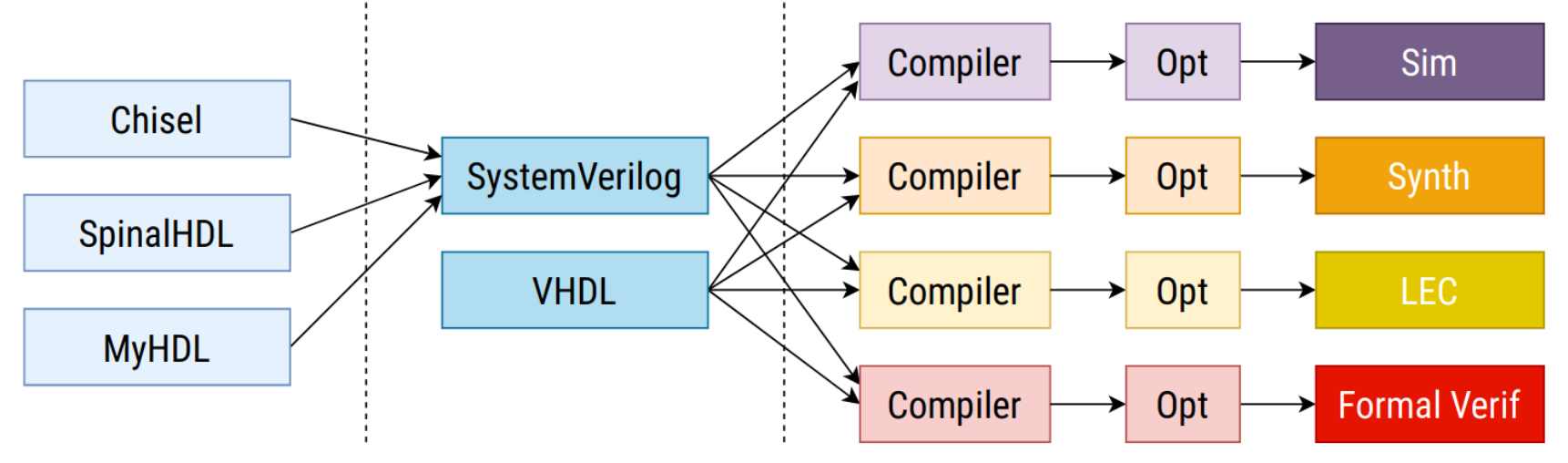
Существующая иерархия инструментов
Проблема такого подхода не только в удобстве. Дело в том, что и Verilog и VHDL — очень большие и сложные. Спецификации этих языков буквально содержат тысячи страниц текста. По этой причине они крайне неудобны как формат промежуточного представления.
На схеме выше видно, что каждый из инструментов вынужден независимо реализовывать парсер входного языка и необходимые оптимизации, что при таком объеме спецификации означает неминуемые разночтения, ошибки и в итоге — проблемы совместимости инструментов.
Но в отличие от HTML, здесь мы говорим не о проблеме различающейся или некорректной отрисовки элементов страницы в разных браузерах, а потенциально о запоротой серии микросхем и убытках в миллионы долларов.
Имеющиеся различия в интерпретации входных языков разными инструментами приводят к тому, что разработчики оказываются вынужденными придерживаться строгих (хотя и трудно формализуемых) правил, какие языковые конструкции использовать и как добиться того, чтобы и симулятор, и синтезированный прототип на ПЛИС, и конечное устройство работали одинаково и предсказуемо.
На деле же получается, что симулятор выполняет код на основании одной интерпретации, формальный верификатор — второй, синтезатор — третьей. А программист, глядя на все это великолепие должен полагать, что наверное, дизайн все же верный, раз все инструменты «договорились».
Промежуточное представление
Идея промежуточного представления (Intermediate Representation, IR) давно применяется и хорошо себя зарекомендовала в компиляторах. К примеру, и LLVM и GCC используют промежуточные представления LLVM IR и GIMPLE. Функциональные языки часто используют представление CPS. Байткод JVM тоже можно отнести к IR. Авторы применили тот же подход к языкам описания аппаратуры.
IR позволяет привести входной язык в удобную для компилятора форму и эффективно выполнять всевозможные трансформации и оптимизации кода, не нарушая семантику исходного языка.
Надо сказать, что на данный момент уже существует с десяток промежуточных представлений для языков описания аппаратуры, но по словам авторов, ни одно из них не может выступать в роли универсального:

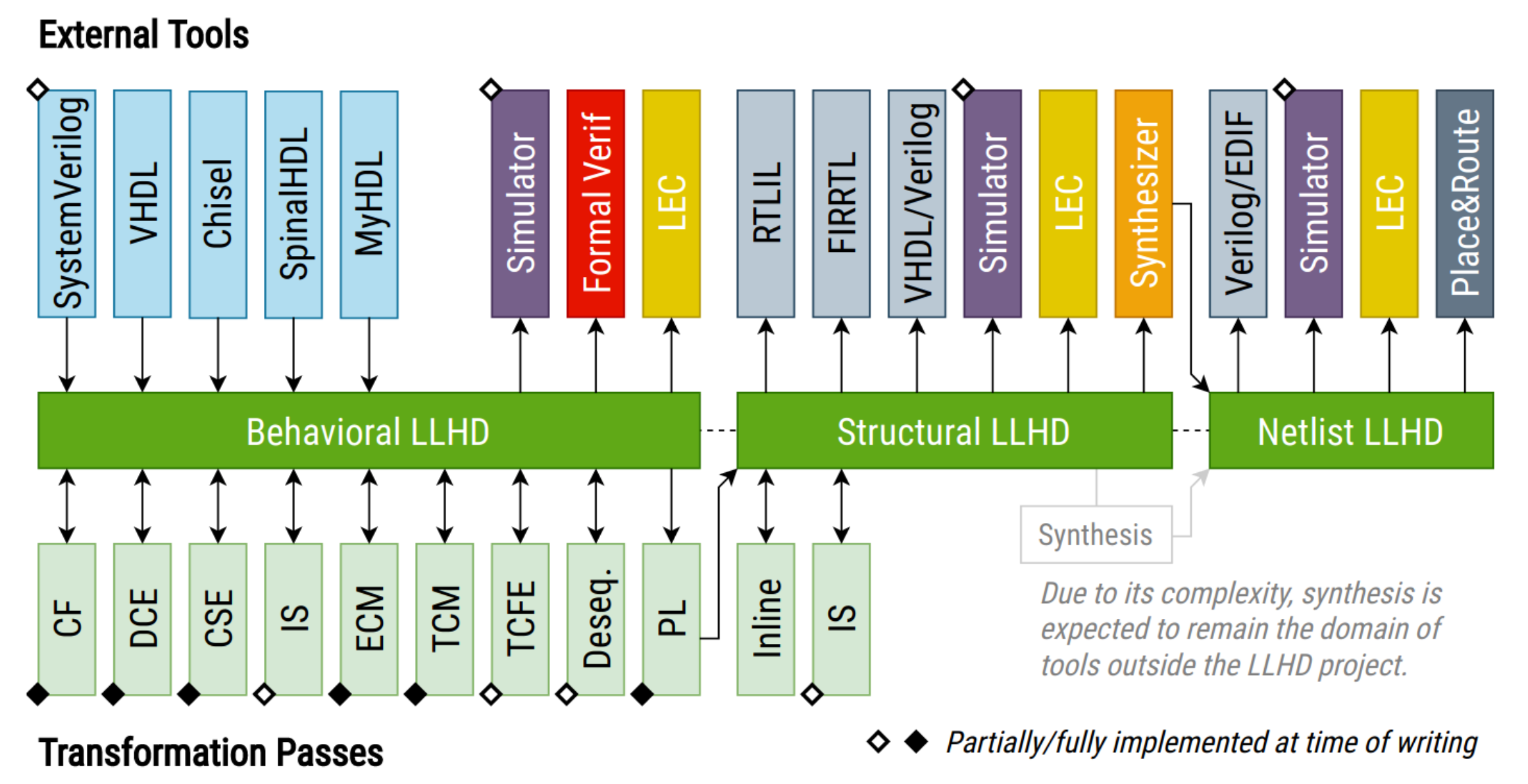
Можно выделить несколько уровней описания архитектуры: поведенческий (behavioral), структурный (structural) и уровень сетей и вентилей (netlist):
- Поведенческий уровень позволяет описать модель и состояние электронной схемы в виде, максимально близком к высокоуровневым языкам описания аппаратуры. Позволяет реализовать конструкции для симуляции и тестирования с использованием ассертов, файлового ввода-вывода или интринсиков для формальной верификации.
- Структурный уровень ограничивает описание частями, выражающими отношения входов с выходами. Сюда относится практически все, что может быть описано в виде сущностей (см. ниже).
- Уровень сетей и вентилей еще более ограничивает доступные средства и сводится к описанию и соединению цифровых схем. Позволяет создание сущностей, сигналов, соединений, линий задержек и инстанциирования подсхем.
Из таблицы выше видно, что существующие IR в основном используются для структурного описания и синтеза. В то же время LLHD поддерживает все уровни описания и является полным по Тьюрингу. LLHD позволяет в точности передать все аспекты языков высокого уровня, включая конструкции для симуляции, верификации и тестирования. Все вместе это позволяет использовать LLHD на всех этапах разработки.
От LLVM к LLHD
LLVM — это универсальный фреймворк разработки компиляторов, позволяющий сравнительно легко реализовать поддержку своего языка путем трансляции его в специальное промежуточное представление — IR код LLVM. Вопреки названию, он не имеет отношения к виртуальным машинам, хотя и может использоваться для их создания. Почитать про LLVM можно на Википедии или здесь на Хабре. В качестве введения могу порекомендовать один из моих докладов с конференции С++ Siberia и статьи на тему разработки JIT VM для языка Smalltalk.
Важно отметить, что трансляцию в IR код нужно сделать только один раз после разбора входного языка. Дальше LLVM будет работать сама. При этом программист концентрируется на семантике своего языка, тогда как LLVM берет на себя всю грязную работу по преобразованию IR кода в инструкции процессора конечной архитектуры и сопутствующим оптимизациям: инлайнингом функций, удалением «мертвого» кода, разворачиванием и векторизацией циклов, аллокацией регистров, выбором инструкций и т.п. Прелесть в том, что единожды реализовав транслятор нашего языка в IR код, мы бесплатно и «из коробки» получаем поддержку всех целевых архитектур и форматов исполняемых файлов, с которыми LLVM умеет работать.
В основе лежит нотация SSA и разделение кода на т.н. базовые блоки, тело каждого из которых не содержит ветвления, но оканчивается инструкцией перехода. Такая организация кода здорово упрощает анализ и позволяет эффективно выполнять трансформации.
Процесс обработки IR кода в LLVM выглядит как серия проходов трансформации. На каждом проходе выполняется та или иная операция над IR кодом. Существует большое количество стандартных проходов трансформаций, общих для всех языков, которые позволяют оптимизировать код или подготовить его к трансляции в инструкции:
- Inlinine Expansion — внедряет тело вызываемой функции вместо инструкции вызова; часто открывает дорогу другим оптимизациям
- Dead Code Elimination — удаляет из IR кода недостижимые базовые блоки
- Loop Invariant Code Motion — выносит за пределы цикла блоки, инвариантные по отношению к переменным индукции
- Loop Unrolling — разворачивает несколько итераций цикла для лучшей утилизации ресурсов процессора и удобства векторизации
- Constant Folding и Constant Propagation — проталкивают константы «вниз» по графу, заменяя арифметические подвыражения на статически вычисленный результат
- Loop Autovectorization — автоматически векторизует скалярные циклы
- и многие другие
LLHD унаследовал структуру IR кода LLVM, дополнив ее своими инструкциями и трансформациями, специфичными для разработки аппаратуры. В то же время, многие существующие конструкции и проходы трансформаций остались практически неизменными.
LLHD позволяет использовать один и тот же IR код и для симуляции и для синтеза.
Для симуляции дизайна IR код выполняется интерпретатором, либо средствами LLVM производится JIT-компиляция IR кода в нативные инструкции процессора с последующим их выполнением.
Для преобразования поведенческого представления в структурное применяются разработанные авторами проходы трансформации, нацеленные на замещение императивных конструкций на регистровую логику. Впоследствии структурное представление может напрямую быть использовано для синтеза.
IR код LLHD
По аналогии с другими HDL языками в LLHD существует три вида компонентов: функции, процессы и сущности.
Функции отображают 0 или больше входных значений на 0 или 1 выходное значение. Функции используются для тестирования и переиспользования логики в других компонентах. Функции могут вызывать другие функции, содержать рекурсию и позволяют сформулировать действие входов на выход в терминах SSA. Функции не могут быть синтезированы непосредственно, поскольку не имеют прямых аппаратных аналогов. С точки зрения времени симуляции функции исполняются мгновенно и не могут взаимодействовать с сигналами или приостанавливать выполнение.
Процессы, напротив, могут взаимодействовать со временем. Так же как и функции, процессы формулируются в терминах потока управления. Процессы представляют собой полные по Тьюрингу подпрограммы, описывающие состояние и поведение цифровой схемы. Каждый процесс представляет собой схему с 0 или больше входами и выходами. И входы и выходы должны быть заданы сигналами. При инициализации управление передается на первый базовый блок и, так же как в функциях, продвигается в соответствии с инструкциями управления. Дополнительно, процессы могут приостанавливать выполнение на определенный промежуток времени, до смены сигнала или навечно. В отличие от функций, процессы существуют все время жизни схемы и никогда не возвращают управление.
Сущности представляют собой граф потока данных и не содержат управления. На момент инициализации выполняются все инструкции сущности, далее выполнение происходит при смене состояния одного из сигналов. Сущности используются для описания структуры схемы и построения иерархии дизайна путем аллокации регистров и сигналов и инстанциирования других процессов и сущностей.
Размер статьи не позволяет подробно рассмотреть структуру и синтаксис IR кода LLHD. Поэтому мы кратко пробежимся по основным моментам на примере реализции простейшего синхронного аккумулятора, который получает входное значение и выставляет сумму на выходной защелке:

Здесь объявляется сущность acc с тремя входными сигналами (однобитный синхросигнал clk, 32-битный инкремент x и однобитный разрешающий сигнал en) и одним 32-битным выходным сигналом (q). В теле сущности объявляется два сигнала d и q, с помощью которых связываются инстанции триггерного и комбинационного процессов, реализующих логику аккумулятора. Начальное состояние сигналов после сброса задается константой zero.

Триггерный процесс acc_ff задает условия срабатывания схемы по отношению к фронту синхросигнала clk. Инструкция prb получает текущее значение сигнала в данный квант времени; wait приостанавливает выполнение процесса до наступления события (времени либо изменения состояния какого-либо сигнала) и передает управление по указанной метке; neq и and реализуют операторы "не равно" и "логическое и"; в зависимости от параметров br совершает условную или безусловную передачу управления в указанные базовые блоки; drv задает будущее значение сигнала в последующем кванте.

Комбинационный процесс acc_comb получает на вход текущее значение аккумулятора q, инкремент x и сигнал разрешения en. В зависимости от значения сигнала разрешения, процесс либо выставляет на выход текущее значение без изменений, либо численно складывает (add) прочитанные значения qp и xp.
В приведенном виде код может использоваться для верификации дизайна и для симуляции. Однако, аппаратура ничего не знает о квантах времени и не может напрямую реализовывать инструкции потока управления. Поэтому для преобразования кода к удобному для синтеза виду, производятся следующие трансформации:
Проходы трансформации LLHD
- Сокращается комбинационная сложность операций: выполняется свертка констант (CF), удаление мертвого кода (DCE) и локальные peephole оптимизации инструкций (IS)
- Арифметика вытесняется «наверх» из базовых блоков и циклов (ECM)
- Инструкции доступа к сигналам вытесняются из базовых блоков (TCM)
- Удаляются инструкции потока управления и phi заменяются на мультиплексоры (TCFE)
- Тривиальные процессы заменяются на сущности
- Происходит определение триггеров и защелок
После указанных трансформаций IR код принимает следующий вид:

Видно, что в теле сущности осталась только комбинационная логика и регистровые операции. В таком виде код уже может быть синтезирован на ПЛИС.
Оценка производительности
Авторы провели серию тестов в которых сравнили производительность эталонного интерпретатора LLHD, ускоренного JIT-симулятора LLHD и неназванного проприетарного HDL симулятора. Все три инструмента получали на вход один и тот же HDL дизайн, который исполнялся на проприетарном симуляторе непосредственно, а для LLHD был предварительно оттранслирован без оптимизаций с помощью разработанного авторами компилятора Moore.

В своей статье авторы утверждают, что все три варианта демонстрировали одинаковые результаты симуляции цикл-в-цикл. При этом на некоторых из дизайнов прототип JIT-симулятора LLHD показал производительность в 2.4 раза лучше, чем десятилетиями полируемый проприетарный симулятор, хотя на полномасштабной симуляции ядра RISC-V проприетарный симулятор заметно вырвался вперед.
Авторы считают, что это очень хороший результат и объясняют отставание последнего теста кумулятивным эффектом отсутствия оптимизаций в Moore. В будущем можно ожидать сокращения разрыва и еще большей производительности по мере реализации оптимизаций. Главное по их мнению то, что уже сейчас LLHD позволяет достоверно передать все детали дизайна и симуляции даже для такого крупного проекта как RISC-V.
Выводы
Авторы показали, что техники, традиционные для компиляторов языков программирования, могут с успехом быть применены и для языков описания аппаратуры. Был разработан новый промежуточный язык описания аппаратуры, прототипы транслятора из SystemVerilog, эталонный интерпретатор и JIT-симулятор LLHD, показавшие хорошую производительность.
Авторы отмечают следующие достоинства такого подхода:
- Существующие инструменты могут быть значительно упрощены путем перевода на LLHD в качестве рабочего представления
- Разработчикам новых языков описания аппаратуры достаточно один раз оттранслировать код программы в IR LLHD и бесплатно получить все остальное, включая оптимизации, поддержку целевых архитектур и окружения разработки
- Исследователи, занимающиеся алгоритмами оптимизации логических схем или размещения компонентов на ПЛИС могут сконцентрироваться на своей основной задаче не тратя время на реализацию и отладку парсеров HDL
- Вендоры проприетарных решений получают возможность гарантированно-бесшовной интеграции с другими инструментами экосистемы
- Пользователи получают уверенность в корректности дизайна и возможность прозрачной отладки по всему тулчейну
- Впервые появляется реальная возможность реализации полностью открытого стека разработки аппаратуры, отражающего последние новшества и эволюцию современных компиляторов
От себя добавлю, что я давно ждал подобного события и очень рад, что ситуация таки сдвинулась с мертвой точки. Очень надеюсь, что этот проект повлечет за собой заметное оживление в сообществе и, наконец, позволит снизить порог вхождения в разработку на ПЛИС посредством реализации новых языков и эргономичных инструментов.
Сомневаюсь, что язык Rust стал бы тем, чем он есть сейчас, не будь у него за спиной миллионов строк кода LLVM и опыта десятилетий открытой разработки компиляторов. Возможно, подобное произойдет и в случае LLHD.
Комментариев нет:
Отправить комментарий